解題記事 | 系統主機 thread 數量暴增

狀況描述
前段時間,一個系統進行版更,版更後隔天監控系統 (Checkmk) 發出了 AP 主機 thread 數量過多 (Number of threads) 的告警。
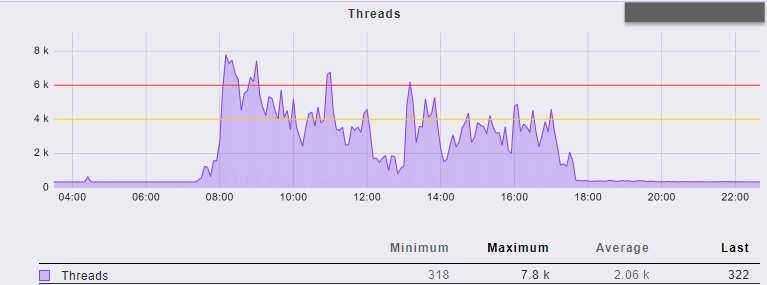
版更前的 thread 數量在上班時間大約落在 400 至 600 間,版更後相同時間卻落在 4000 至 6000 之間,甚至更多,系統的反應也比以往要慢上許多。
釐清原因
版更後有狀況,通常第一時間都會回頭檢視這次版更了哪些東西,這次的版更有幾個項目:
- 修正 1 個 Defect
- AP 主機作業系統升級
- 為開放外網改變系統佈署架構
在 DMZ 1 中增設一台 Web Server,透過轉發到特定服務的方式指向真正的 AP 主機。 - 改變驗證機制
為了提升安全性與可維護性,登入驗證機制改用 OAuth 2.0 的認證授權方式。
逐一釐清每一項調整的嫌疑 (好像偵探)
第 1、2 項因為掌握度算高,很快被排除在外,第 3 項的釐清是先觀察監控系統,發現放在 DMZ 的 Web Server thread 數量很穩定的少,相比於 AP 主機的數量,由此可推斷造成 thread 飆高的原因不在外部了,那麼,就只剩第 4 項了,使用者在系統的請求,應該會觸發驗證 Token 有效的檢查機制,而驗證是否有效需連線到身份證別主機,觀察網路連接應該可以發現一些端倪。
主機是 Linux 主機,透過幾個指令判斷兇手應該就是它
- 查出 tomcat 的網路連接
- 過濾出包含 https 關鍵字的結果
- 印出前一個輸出結果的指定欄位值
- 去除重複列並標示出現次數
- 依照指定欄位倒序排序
觀察 tomcat 的網路連接狀況
netstat -p | grep $pid得到的 output 結果是 tomcat 當下所有的網路連接狀況,從輸出結果中觀察到有不少連接到身份識別主機的連線
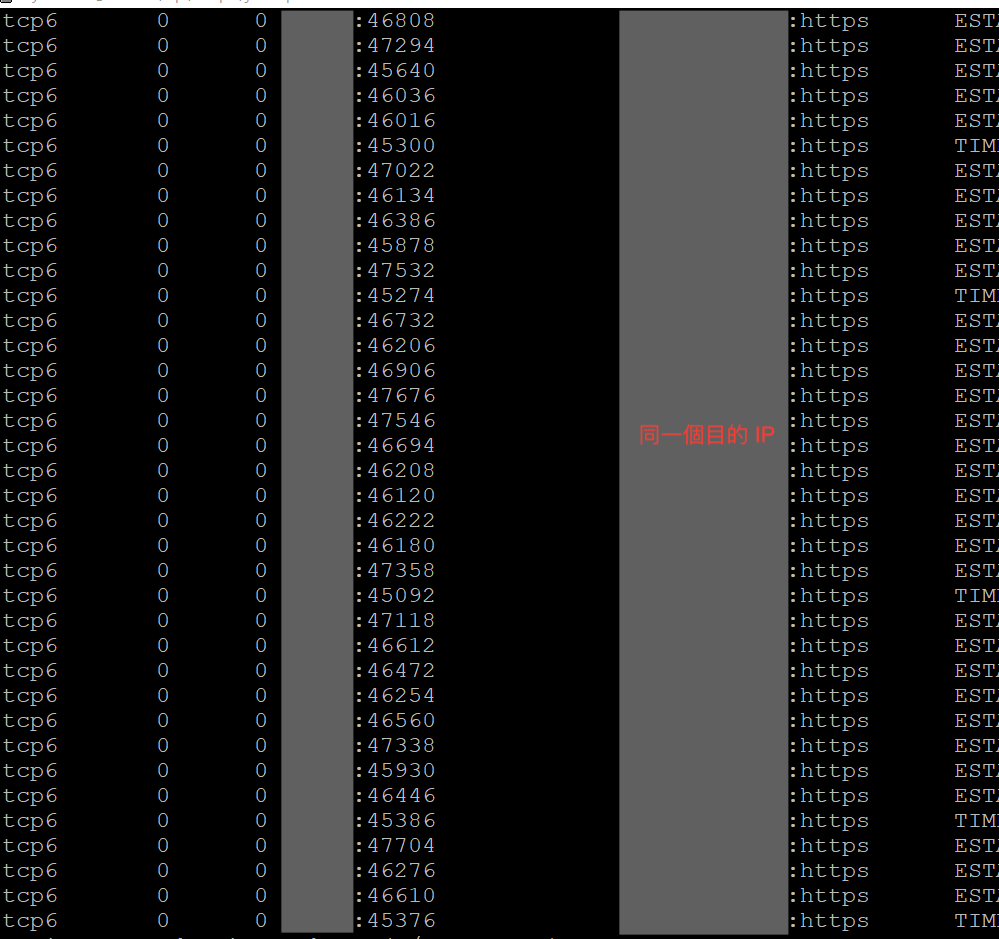
為了有更切確的數據能驗證想法,利用指令將輸出結果作個 summary
netstat -p | grep $pid | grep 'https' | awk '[print $5 "\t" $6}' | uniq -c | sort -nk1 -r
從輸出結果發現連接身份識別主機有 3000 多個連線

上述的指令使用到 pipe (|),簡單理解就是將 pipe 前指令的輸出扔給 pipe 後的指令當作輸入,主要目的是為了將前一個指令的輸出整理一番:
找出 AP Server 的 process
系統用的是 tomcat,習慣上我會直接下指令尋找 tomcat 的 process id
ps aux | grep tomcat從前述指令得到的 output 結果,第 2 個欄位就是 process id,以下將得到的結果以 $pid 表示
當時站台線上人數只有 95 人左右,但是有這麼多與身份識別主機的連線,大致可以推測每個 request 都去跟身份識別主機驗證 token 是否有效,但是數量多到讓人覺得怪,難道每個使用者手速飛快?
該系統是使用 Java 開發的系統,要驗證 token 是否有效應該會經過驗證的 Filter 2 進行檢查,針對這個驗證的 Filter 也會設定有哪些類型的資源需要檢查,實際檢查該系統的 web.xml 檔案
<filter-mapping>
<filter-name>AuthenticationFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
確實有一個驗證的 Filter,名為 AuthenticationFilter,而底下的那行 url-pattern 設置為 /*,這代表所有的資源 都要經過驗證,包含圖檔、載入的 js 與 css,想像一下,使用者開啟一個畫面,背後代表的可能是 request 20-30 個資源,每個資源都會去跟身份識別系統確認一次。
查到這個階段,大約已可以確定問題就在這個設定了,那麼,該怎麼解決這個問題呢?
解決方法
解決的方式其實不難,主要是把應該經過驗證的資源明確下來,將 url-pattern 的 /* 調整為明確的資源類型,那麼,需要經過驗證的資源是什麼呢?
一般來說程式類的檔案會有商業邏輯、資料庫存取等處理,大多是需要經過驗證的,再者可能是一些需要登入狀態才能存取的附加檔案,實際的設定需要和該系統負責人員討論。
<filter-mapping>
<filter-name>AuthenticationFilter</filter-name>
<url-pattern>/*.jsp,/files/*</url-pattern>
</filter-mapping>
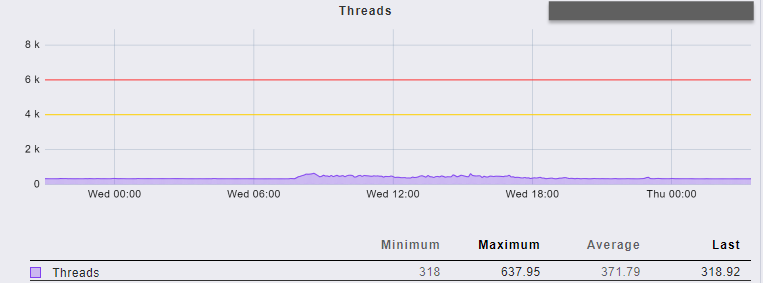
調整後重啟服務,觀察一陣子,thread 數下降許多且穩定
後記
工作中多少會遇上一些系統問題需要排除,往往解決問題後,以口頭或訊息的方式經驗分享,花愈多時間,留在心裡 (腦裡) 的時間愈長,但其實時間久了還是會忘記,更不用說只是聽分享但沒有實際操作的人了,也因此觸發了寫這篇筆記的開關,將釐清問題的思路和手法記錄下來。
解決技術問題後,更需要做個整理,對外,將問題排除前後的狀況作個對比,將相關的資訊傳達給提報問題的人;對內,分享釐清問題、找出根因的手法,與開發團隊復盤檢視有沒有可以優化的點,發起改善計畫與執行,形成團隊好的循環。



