[紀錄] 初試 OpenClaw
![[紀錄] 初試 OpenClaw](https://images.unsplash.com/photo-1656680632373-e2aec264296b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHNvZnR3YXJlJTIwaW5zdGFsbHxlbnwwfHx8fDE3NzQxODE2MTl8MA&ixlib=rb-4.1.0&q=80&w=1200)
夯了很久的 OpenClaw,近期開始出現了退安裝潮,我卻正要開始嘗試使用。
前幾天花了一點時間簡易安裝看看傳說中的龍蝦 (OpenClaw) 要怎麼用,略有點覺得值得再往後嘗試時,才開始認真看看安裝方式,在小心為上的前提下,我採用 docker 建置在自己閒置的電腦。
在 docker-compose.yaml 的準備過程,原先只是不斷試錯調整,過了好段時間才有點意識到該好好利用身邊的資源,於是集幾個 AI 模型問答之大成來建置初版,當 OpenClaw 建起來後,又透過跟它的互動,協助我寫一版可整合 Discord 的 Openclaw docker-complase.yaml 自用。(參考)
Gateway Token & Pairing
如果沒有特別改設定,當啟動 container 後,透過 http://localhost:16789 會導向登入頁
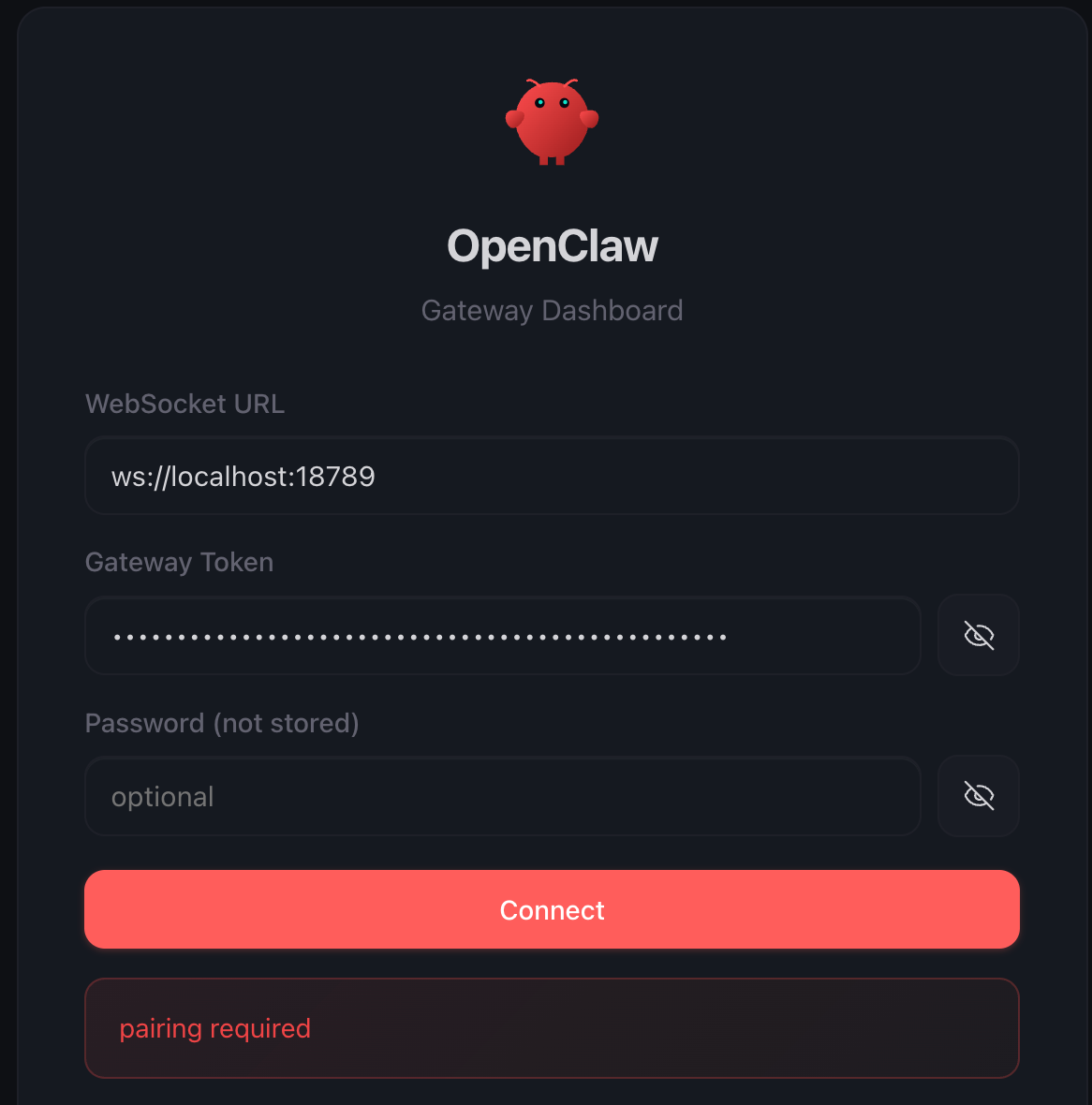
登入時會遇到 2 個情況
- 預帶的 Gateway Token 跟 openclaw 初始產生的不同
我的處理方式是到 openclaw.json 中找到 gateway 的 token 複製到登入頁貼到Gateway Token 欄位 - Gateway Token 正確後按 Connect 會在下方出現 pairing reaquired
我的處理方式是進到 container 中執行核准的指令
# 進入 contaienr
docker exec -it oepnclaw /bin/bash
# 在 container 中核准裝置
openclaw devices approve模型設定
接著是得設定 OpenClaw 要用哪個模型,在這次嘗試中,我使用的是 OpenAI Codex OAuth,在 container 中透過指令取得 OAuth 網址openclaw models auth login --provider openai-codex
在瀏覽器打開網址,完成登入動作後,網頁會導向如下方格式網址http://localhost:1455/auth/callback?code=xxx
將網址複製起來,回到 container 中會看到上一個指令在等待回填 Paste the redirect url,將網址貼上即可通過驗證,指令會回傳預設可用的模型名稱,接著應該會自動重啟 (一開始我還以為我把它搞壞了...)

重啟後再進入一次 container,設定預設的模型 (可以參考通過驗證之後的訊息)
openclaw models set openai-codex/gpt-5.x
Say Hi 設定角色
到這一步完成,就可以透過 OpenClaw 的 UI 與模型對話了。第一次跟 OpenClaw 應該會提示需要完成角色設定,寒喧一番後就可以啟動和小蝦一起工作的愉悅(?)旅程了。
後記
截至目前對 OpenClaw 的認識仍少,在沒有足夠了解配置用途前還是略不安心,安裝在隔離環境只是一層防護,接著要找幾個小題目來了解它的功能與機制,尤其是安全性 (使用到許多有帳號資訊的工具),持續修正目前的安裝檔及設定。



