筆記 | 在 Ubuntu 22.04 安裝 Kubernetes Cluster

許多網路文章中都有安裝 kubernetes cluster 的教學,也因為版本更迭,爬了很多的文章、裝了非常多次,整理以下的筆記,幫自己防忘記。
實作環境
- 主機 (VM) 3 台,一台 master、兩台 node
- pve-master
- pve-node1
- pve-node2
- 作業系統 Ubuntu 22.04
- Container Runtime 選擇 containerd.io
筆記的幾個大步驟,有些是所有節點都要做,有些則否,整理如底下的表格:
| Step | pve-master | pve-node1 | pve-node2 |
|---|---|---|---|
| 安裝前置 | V | V | V |
| 安裝 Container Runtime | V | V | V |
| 安裝 kubeadm | V | V | V |
| 建立 Kubernetes Control-Plane Node | V | ||
| 建立 Kubernetes Worker Node | V | V |
安裝前置
重新載入設定以生效
sudo sysctl --system載入 k8s 需要的核心模組
sudo modprobe overlay
sudo modprobe br_netfilter調整 iptables 規則及啟用 IPv4 封包轉發
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF關閉系統交換區
參考 kubeadm 的安裝前說明
sudo swapoff -a
#目的是註解 /etc/fstab 裡的 swap
sudo sed -i '/swap/s/^/#/' /etc/fstab更新系統套件至最新
sudo apt update
sudo apt upgrade安裝 Container Runtime
啟動 Container Runtime
sudo systemctl start containerd
sudo systemctl enable containerd將設定檔中的 SystemdCgroup 改為 true
sudo sed -i 's/SystemdCgroup \= false/SystemdCgroup \= true/g' /etc/containerd/config.toml產生 containerd 設定檔 (依預設值)
containerd config default | sudo tee /etc/containerd/config.toml更新套件資訊,安裝 containerd.io
sudo apt update
sudo apt install containerd.io加入 Docker 套件伺服器
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null取得 Docker for Ubutnu 的 GPG key
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc安裝需要的套件
OS 預設應該有安裝,但如果在安裝 OS 時有自行選擇套件,就需要再確認
sudo apt install ca-certificates curl安裝 kubeadm
更新套件資訊,安裝 kubelet、kubeadm、kubectl
sudo apt update
sudo apt install -y kubelet kubeadm kubectl#設定套件不更新
sudo apt-mark hold kubelet kubeadm kubectl加入Kubernetes 套件伺服器
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list取得 Kubernetes 的 GPG key
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg建立 Kubernetes Control-Plane Node
安裝 Flannel,負責分配 cluster 中每個 pod 的 IP
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml便於非 root 用戶後續使用 kubectl 操作子節點
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config初始化 Kubernetes control-plane node
sudo kubeadm init --pod-network-cidr=10.244.0.0/16執行成功後會有一串提示訊息,將最後一段的 kubeadm join 複製備存,如以下的範例 (參考用,實際建置需複製 kubeadm init 成功後的提示訊息),子節點加入 cluster 時使用
sudo kubeadm join 10.10.1.3:6443 --token diwo8f.sm21fe24mj7c4mv2 --discovery-token-ca-cert-hash sha256:568c62d5c74a8e7b6b57e0fd4268365a896d3f2c78a60616bb6fc47154b4352c建立 Kubernetes Worker Node
初始化 Kubernetes Worker Node,加入前一步建立好的 kubernetes cluster
以下範例僅參考,實際應該使用在 master 執行 kubeadm init 成功後產生的指令
sudo kubeadm join 10.10.1.3:6443 --token diwo8f.sm21fe24mj7c4mv2 --discovery-token-ca-cert-hash sha256:568c62d5c74a8e7b6b57e0fd4268365a896d3f2c78a60616bb6fc47154b4352c完成前述步驟就已經建置起一個 Kubernetes Cluster 了,回到 Master 執行指令可以查看
kubectl get nodes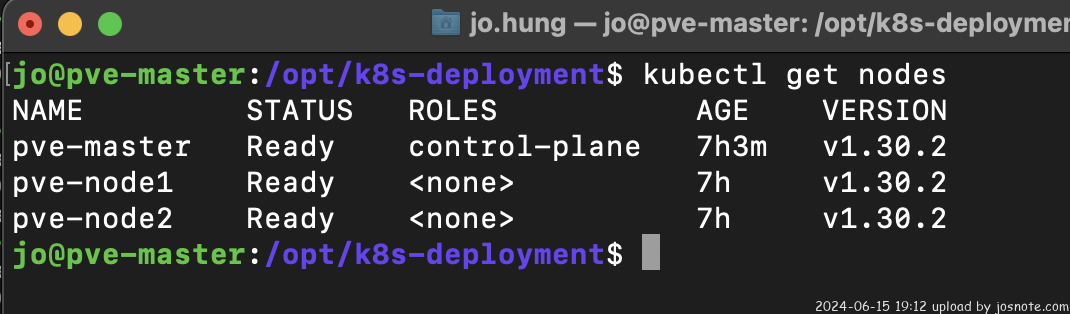
參考資料



